

git使用指南
用github写静态博客老是需要与git打交道,所以整理一篇git使用指南,后面要是遇到新问题了也会继续补充
git常用命令
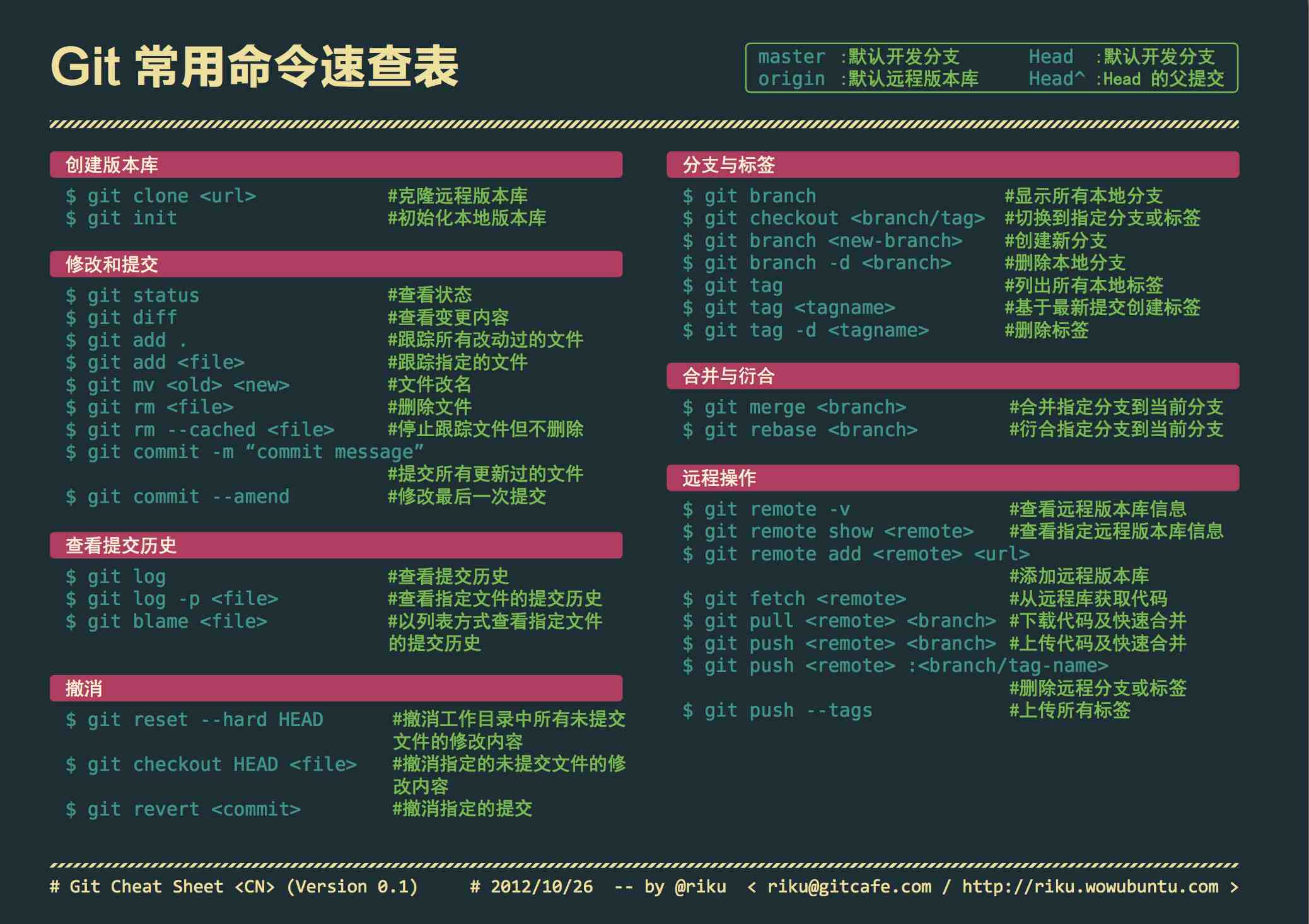
git一些常用命令解析
git 回退代码到某次 commit
1、查询需要回退的 commit 记录
使用如下命令查询提交记录: git log
2、回退代码到某次 commit
git reset —hard commitID(其中,commitID 根据实际情况,确定需要回退的 commit 记录ID。)
3、本地 Git 代码推送到远程 Git 仓库 将回退后的代码,同步推送到远程 Git 仓库,命令如下: git push origin remoteBranchName
git fetch 与 git pull 的区别
git pull 是 git fetch 和 git merge 的组合。 它会从远程仓库获取更新,并自动将这些更新 合并 到你当前所在的分支上。 git pull 是一个 更直接 的操作,它不仅会获取远程更新,还会直接合并到你本地的分支。
git fetch 会从远程仓库获取所有的更新(新的提交、分支等),但不会对你本地的工作分支产生任何影响。 它只会更新本地的远程跟踪分支,你可以在本地查看远程仓库的更新内容,但不会直接合并到当前的工作分支。需手动执行merge操作
123456git branch -a //通过 git branch -a 查看所有分支(包括远程分支)
//可以得到以下的分支
* main
remotes/origin/main
remotes/origin/feature/login
git 概述
什么是git
Git 是一个分布式版本控制系统,用于跟踪文件的变更、协作开发和管理项目历史记录。
它可以帮助开发者有效地管理源代码的版本,确保不同版本之间的差异可以被追踪,便于多人的协作和代码合并。
git历史
同生活中的许多伟大事件一样,Git 诞生于一个极富纷争大举创新的年代。
Linux 内核开源项目有着为数众广的参与者。
绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。
到 2002 年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,于是整个项目组开始启用分布式版本控制系统 BitKeeper 来管理和维护代码。
到 2005 年的时候,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了免费使用 BitKeeper 的权力。
这就迫使 Linux 开源社区(特别是 Linux的缔造者 Linus Torvalds )不得不吸取教训,只有开发一套属于自己的版本控制系统才不至于重蹈覆辙。
他们对新的系统订了若干目标:
• 速度
• 简单的设计
• 对非线性开发模式的强力支持(允许上千个并行开发的分支)
• 完全分布式
• 有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
git的几个核心概念
工作区、暂存区、版本库、远程仓库
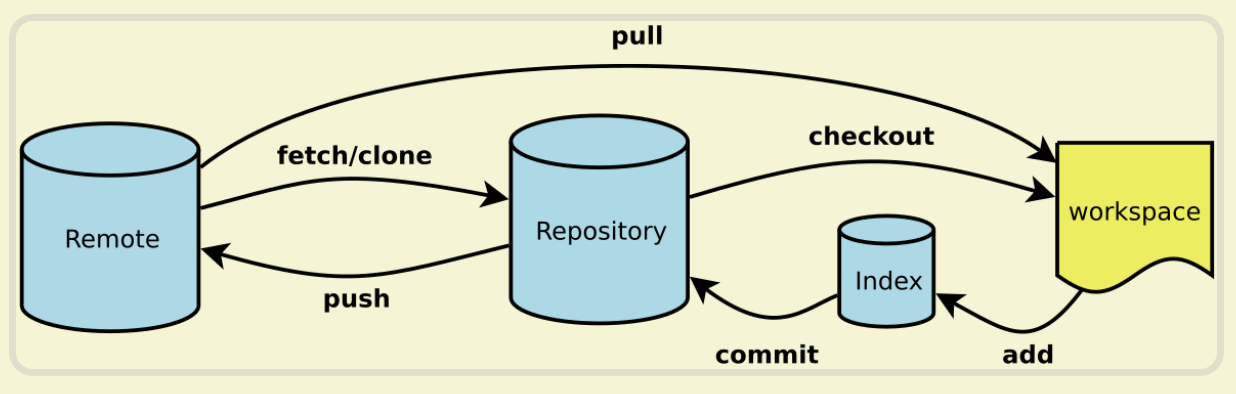
Workspace:工作区 Index / Stage:暂存区 Repository:仓库区(或本地仓库) Remote:远程仓库
工作区(Working Directory)
工作区是你在本地计算机上的项目目录,你在这里进行文件的创建、修改和删除操作。工作区包含了当前项目的所有文件和子目录。
特点:
显示项目的当前状态。 文件的修改在工作区中进行,但这些修改还没有被记录到版本控制中。
暂存区(Staging Area)
暂存区是一个临时存储区域,它包含了即将被提交到版本库中的文件快照,在提交之前,你可以选择性地将工作区中的修改添加到暂存区。
特点: 暂存区保存了将被包括在下一个提交中的更改。 你可以多次使用 git add 命令来将文件添加到暂存区,直到你准备好提交所有更改。
版本库(Repository)
版本库包含项目的所有版本历史记录。
每次提交都会在版本库中创建一个新的快照,这些快照是不可变的,确保了项目的完整历史记录。
特点: 版本库分为本地版本库和远程版本库。这里主要指本地版本库。
本地版本库存储在 .git 目录中,它包含了所有提交的对象和引用。
实例
123git add file.txt //将修改添加到暂存区
git commit -m "Update file.txt" //将暂存区的修改提交到本地版本库
git push origin main //将本地提交推送到远程仓库
git分支(branch)
git的对象模型
Git 的存储机制是基于对象模型的。
每个文件在 Git 中都被看作是一个对象,而这个对象的全局唯一标识符(SHA-1 哈希值)即为其对象名。
Git 存储的核心单元是一系列的对象,包括 blob、tree、commit 和 tag。
1.Blob(Binary Large Object)
作用:Blob 对象用于存储文件的内容。
存储内容:它只包含文件内容,没有文件名、路径、权限等信息。
命名:Blob 对象的文件名是它的 SHA-1 哈希值。
2.Tree(树对象)
作用:Tree 对象用于表示文件夹(目录)的结构。
存储内容:它包含文件和子目录的指针。每个指针指向一个文件(Blob)或一个子目录(Tree)。
结构:一个 Tree 对象实际上是一个目录的清单,记录了文件和目录的名称、类型(文件或子目录)以及它们的哈希值(分别是 Blob 或 Tree 的哈希)。
3.Commit(提交对象)
作用:Commit对象用于保存提交的元数据(如提交信息、时间戳、提交者等),并且指向一个或多个 Tree 对象(代表文件夹的快照),从而建立提交与文件内容之间的联系。
存储内容:Commit 对象存储的是1.指向commit当时的 Tree 对象的指针,2.指向上一次提交的父提交指针(如果是首次提交则没有父提交指针),以及一些提交相关的元数据。
git是如何存储内容的
Git 利用这些对象模型来存储整个项目的历史版本。它采用了一种称为“有向无环图”的结构来组织文件的历史。 1.在 Git 中,每个 Commit 对象都包含一个或多个父提交的指针。 通过这种方式,Git 可以跟踪每个提交的前一个提交,从而构建一个完整的文件历史链。
2.在每次提交时,Git 会创建一个新的 Commit 对象,其中包含了指向当前对应的 Tree 对象的指针。 这个 Tree 对象记录了提交时的文件树结构。通过这种方式,Git 可以追溯每个提交的文件内容和目录结构。
3.当我们在工作目录中修改文件后,可以使用 git add 命令将修改后的文件添加到暂存区(Stage)。 然后使用 git commit 命令创建一个新的 Commit 对象,将当前的暂存区内容存储为一个新的 Tree 对象,并将其链接到前一个 Commit 对象。这样,文件的历史版本就可以被记录并保留下来。
Git 的存储机制还包括一些优化措施来提高效率。例如,对于大文件和二进制文件,Git 会使用差异压缩技术来存储它们的差异,而不是存储整个文件的副本。这样可以节约存储空间,并减少传输和复制的时间。
另外,Git 还有一个称为“分支”的概念。分支实际上是指向某个 Commit 对象的指针,它表示一个独立的开发线。当我们在分支上进行提交时,Git 只会更新该分支的指针,而不会影响其他分支的历史。这使得并行开发和多人协作变得更加方便。
git是如何缩小存储内容的
然 Git 在每次提交时保存文件的完整内容(即快照),但它并不是简单地重复保存相同的文件内容,而是通过以下几个机制来节省空间:
哈希值和去重机制
Git 使用 SHA-1 哈希算法来标识每个文件的内容。 文件内容相同的文件,哈希值也相同。 这意味着如果项目中有多个文件内容完全相同,Git 只会保存一份文件内容(即一个 Blob 对象),而不会重复存储它们。
对象存储和压缩
Git 的对象存储是非常高效的。所有的 Git 对象(包括 Blob、Tree、Commit 等)都存储在 .git/objects 目录下,并且这些对象会经过压缩和优化存储,以节省空间。
每个 Git 对象都是通过 SHA-1 哈希值进行唯一标识的。例如,Git 会将文件内容 “Hello Git!” 保存为一个对象(Blob),这个对象的哈希值是其内容的唯一表示。 Git 使用一种叫做 zlib 压缩算法的技术,对这些对象进行压缩。即使是不同版本的文件,如果文件内容有很大相似,Git 会通过压缩算法进一步减少存储空间。 另外,Git 会将多个小文件合并到一个存储块中,这样可以进一步减少文件存储的开销。
对象合并(Pack 文件)
Git 会定期将分散存储的对象合并为一个更高效的存储格式,称为 pack file(打包文件)。 当 Git 发现某些对象(如 Blob 对象)很相似时,它会将它们存储在一个单独的压缩文件中,进一步节省存储空间。